Event driven design (part 1)/ By Nima Shokouhfar

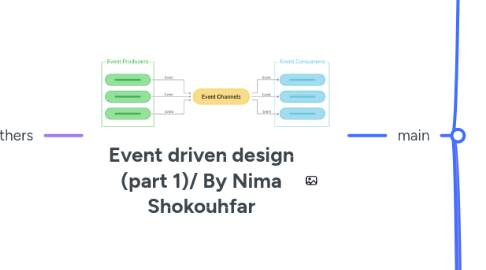
This mind map outlines the core concepts of an event-driven system using RabbitMQ: Event Schema: Defines the structure for events, including attributes like event_id, aggregate_id, event_type, and timestamp. Versioning ensures backward compatibility. Event Versioning: Helps track schema changes over time while maintaining old handlers, allowing reconstruction of past events. Error Handling: Suggests returning 202 status for asynchronous processing, with notification options like callback U...

1. others
1.1. styles
1.1.1. bad
1.1.2. good
1.1.3. not as good
1.1.4. not as bad
1.1.5. important
1.1.6. warning
1.1.7. link
1.2. AUTHOR
1.2.1. Nima Shokouhfar
1.2.1.1. Linkedin
1.2.1.1.1. Follow me on LinkedIn to stay updated on my latest professional insights and tech projects!
1.2.1.2. Youtube
1.2.1.2.1. code with nima
1.2.1.2.2. ideariver
1.2.1.3. Medium
1.2.1.3.1. ✍️ Follow me on Medium to read my latest articles on tech, coding, and innovation!
1.2.1.4. Github
1.2.1.4.1. ⭐️ Give my projects a star on GitHub and explore my repositories to discover new tools and innovations!
1.2.1.4.2. 💖 Sponsor me on GitHub to support my open-source contributions and help me create even more useful projects!
1.2.1.5. upwork
1.2.1.5.1. 💼 Hire me on Upwork for freelance projects. Let’s work together to bring your tech ideas to life!
1.2.1.6. main website: ideariver.ca
1.2.1.6.1. 🚀 Visit IdeaRiver.ca for all my latest projects, blogs, and ways to connect!
2. main
2.1. general
2.1.1. Event schema
2.1.1.1. example
2.1.1.1.1. openapi: 3.0.0 info: title: Event Sourcing API version: 1.0.0 components: schemas: EventMessage: type: object properties: event_id: type: string description: "Unique identifier for the event" aggregate_id: type: string description: "ID of the entity (aggregate) that this event relates to" aggregate_type: type: string description: "Type of the aggregate, e.g., 'plugin', 'user', etc." version: type: number description: "Version of the aggregate's state after this event" default: 1 event_type: type: string description: "Type of the event, e.g., 'PLUGIN_RUN', 'USER_ACTION'" event_schema_version: type: string description: "Version of the event schema" default: "1.0" source: type: string description: "Origin or source of the event, typically the service name" timestamp: type: string format: date-time description: "ISO 8601 timestamp for when the event occurred" payload: type: object description: "Data related to the event, this varies depending on event type" additionalProperties: true nullable: true # Allows null or undefined user_id: type: string description: "ID of the user initiating the event" required: - event_id - aggregate_id - version - event_type - timestamp - source - event_schema_version
2.1.1.2. examples
2.1.1.2.1. plugin
2.1.1.2.2. Order
2.1.1.2.3. Project
2.1.1.2.4. Task
2.1.1.2.5. Product
2.1.1.3. Agregate id vs type
2.1.1.3.1. example
2.1.1.4. Aggregate Type vs Event Type
2.1.1.4.1. 1. Aggregate Type:
2.1.1.4.2. 2. Event Type:
2.1.2. Event Versioning:
2.1.2.1. It can be helpful to include a version field in your schema,
2.1.2.2. especially if you expect your event schema to evolve over time.
2.1.2.3. This helps maintain backward compatibility when you introduce changes to the schema.
2.1.2.3.1. You keep old event handlers
2.1.3. Error Handling and Event Responses:
2.1.3.1. don't hang for the event to return
2.1.3.1.1. return them 202 accepted status
2.1.3.2. norification options
2.1.3.2.1. If you need to notify the client about the success or failure,
2.1.4. Dead Letter Queues (DLQ
2.1.4.1. What happens if a message fails processing? You should have a DLQ in RabbitMQ to capture failed messages.
2.1.4.2. This allows for investigating failures and retry mechanisms.
2.1.4.3. This will make your system more robust.
2.1.5. Message Acknowledgment:
2.1.5.1. This ensures that if the message is processed successfully, it is acknowledged, and if not, it is either retried or placed in a DLQ.
2.1.6. Monitoring and Tracing:
2.1.6.1. You might want to include event logging and tracing for each message, so you can trace the flow from when it was received to when it was processed. This can be useful for debugging and monitoring.
2.1.7. Timeouts
2.1.7.1. If you're going to wait synchronously for a response from RabbitMQ, ensure you handle timeouts correctly.
2.1.7.2. Otherwise, the API could hang indefinitely if the message is delayed or not processed.
2.2. Event Sourcing
2.2.1. fields
2.2.1.1. Aggregate ID:
2.2.1.1.1. In Event Sourcing, each entity that changes state (called an aggregate) needs to be identifiable. You can use an aggregate_id to link a sequence of events to a specific entity (e.g., a plugin, user, or order).
2.2.1.2. Version:
2.2.1.2.1. It's important to track the version of the state for each aggregate. Every time the state changes, the version number increments, helping you track the order of events for a specific aggregate.
2.2.1.3. Event Versioning:
2.2.1.3.1. As previously discussed, versioning the event structure is crucial to maintain backward compatibility.
2.2.1.4. Causal Links:
2.2.1.4.1. If necessary, you can add fields to link related events together, helping understand causality in complex workflows (e.g., the parent_event_id).
2.2.2. aggregate
2.2.2.1. In Event Sourcing, each entity that changes state (called an aggregate)
2.3. Front end notiofication options
2.3.1. details
2.3.1.1. Polling:
2.3.1.1.1. What it is: The frontend periodically makes requests to the backend to check if the task has completed or if new data is available.
2.3.1.1.2. How it works:
2.3.1.1.3. React Example (Polling)
2.3.1.2. WebSockets:
2.3.1.2.1. What it is:
2.3.1.2.2. How it works:
2.3.1.2.3. code
2.3.1.3. Server-Sent Events (SSE):
2.3.1.3.1. What it is: SSE is a one-way communication method where the server sends automatic updates to the frontend over HTTP.
2.3.1.3.2. How it works:
2.3.1.3.3. React Example (SSE)
2.3.1.3.4. Backend Example (Node.js with Express & SSE)
2.3.1.3.5. code
2.3.2. applications
2.3.2.1. SSE (Server-Sent Events)
2.3.2.1.1. Real-time updates
2.3.2.1.2. , live scores), one-way data streams
2.3.2.1.3. (e.g., notifications
2.3.2.2. WebSockets
2.3.2.2.1. Real-time chat applications
2.3.2.2.2. Live updates (e.g., stock prices)
2.3.2.2.3. Multiplayer games
2.3.2.3. Polling
2.3.2.3.1. Data refresh (e.g., dashboard updates)
2.3.2.3.2. Order status checking
2.3.2.3.3. Live feeds
2.3.2.4. Message Queues
2.3.2.4.1. Background tasks (e.g., sending emails)
2.3.2.4.2. Distributed systems
2.3.2.4.3. Log processing
2.3.2.5. Webhooks
2.3.2.5.1. Payment processing
2.3.2.5.2. CI/CD triggers
2.3.2.5.3. Real-time notifications
2.3.2.5.4. CRM integrations
2.3.2.5.5. Not ok for front end of web application. So many concerns
2.3.2.5.6. Callbacks Using Webhooks callbacks:
2.3.3. Which One to Use?
2.3.3.1. WebSockets are ideal for real-time communication, especially if you need instant updates (like a chat app).
2.3.3.2. Polling is simpler but not as efficient, though it works fine for less frequent updates or if you can't use WebSockets.
2.3.3.3. SSE is a lightweight option for one-way communication and is simpler to implement than WebSockets but isn't as flexible as WebSockets for bidirectional data flow.
2.3.3.4. Webhooks are useful when the backend can notify an external service directly instead of maintaining an open connection.
2.3.3.4.1. Not ok for front end of web application. So many concerns
2.4. API route handlign
2.4.1. best practices
2.4.1.1. raw message
2.4.1.1.1. Why Accepting a Raw Message is a bad Idea:
2.4.1.1.2. solution