
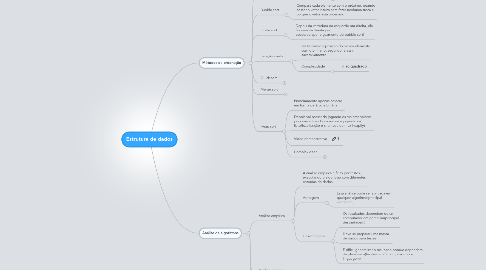
1. Métodos de ordenação
1.1. Inserção direta
1.1.1. Considera o primeiro elemento ordenado, depois ordenada o primeiro e o segundo, depois os tres primeiros, etc
1.1.2. Complexidade
1.1.2.1. n ao quadrado
1.2. Bubble sort
1.2.1. Compara cada elemento com o próximo, quando passar o vetor inteiro sem fazer nenhuma troca é porque o vetor está ordenado.
1.3. Shake sort
1.3.1. Depois da varredura da esquerda pra direita, ele faz uma da direita pra esquerda(aperfeiçoamento do bubble sort)
1.4. Seleção direta
1.4.1. Vai trocando a posição do menor elemento com o primeiro, segundo, e assim sucessivamente
1.4.2. Complexidade
1.4.2.1. n ao quadrado
1.5. Quick sort
1.5.1. Duas variáveis de auxílio são declaradas.Uma na primeira posição da lista e uma no final.
1.5.2. Considera-se o primeiro elemento como sendo o pivô.
1.5.3. Compara a primeira variável com o pivô, se for menor, incrementa. Compara a segunda variável com o pivô, se for maior, decrementa
1.5.4. Quando não pudermos incrementar nem decrementar troca os dois valores
1.5.5. Faça isso ate as duas posições se cruzarem.
1.5.6. Sempre que acabar trocar a variável que começou no final(J) com o pivô
1.5.7. O que está pra trás de J vira uma lista e o que está pra frente vira outra
1.5.8. Link que explica
1.5.9. Complexidade
1.5.9.1. O (nlogn)
1.6. Merge sort
1.6.1. Vai dividindo a lista em 2 até fica um elemento só. Depois começa juntar ordenando
1.6.2. Complexidade
1.6.2.1. O(n log n).
1.7. Heap sort
1.7.1. Primeiramente apenas colocar em forma de árvore binária
1.7.2. Depois vai passando jogando os maiores valores pra cima e tirando da arvore e jogando na lista(Essa função é chamada de max-heapify)
1.7.3. Video demonstrativo
1.7.4. Complexidade
1.7.4.1. O(n log n)
2. Análise de algoritmos
2.1. Análise empirica
2.1.1. A análise empírica é feito por testes, executando o algoritmo com diferentes entradas de dados.
2.1.2. Vantagem
2.1.2.1. Essa análise pode ser aplicada em qualquer algoritmo(principal vantagem)
2.1.3. Desvantagem
2.1.3.1. Os resultados dependem de um computador em particular(principal desvantagem)
2.1.3.2. Deve-se preparar uma massa de dados para testes
2.1.3.3. É difícil generalizar o resultado porque dependerá da plataforma(hardware,SO, compiladores e linguagem)
2.2. Análise dedutiva
2.2.1. Cria uma formulação do problema que permite separar o que é relativo a plataforma e o que é relativo ao algoritmo
2.2.2. A análise é feita com base no código
2.2.2.1. Cada instrução tem um custo específico
2.2.2.2. Cada instrução tem uma frequência que será executada
2.3. Objetivo
2.3.1. Correção
2.3.1.1. Provar no sentido matemático o comportamento de um algoritmo
2.3.2. Desempenho
2.3.2.1. Determinar um modelo que descreve o consumo de recursos em função dos dados de entrada(também chamada de análise de complexidade do algoritmo)
2.3.2.2. Análise de complexidade do algoritmo
2.3.2.2.1. Dois tipos relevantes
2.3.2.2.2. Como encontrar a função?
2.3.2.2.3. A ideia é utilizar uma função(função de complexidade) para expressar um modelo quantitativo que permita prever o comportamento do algoritmo para qualquer conjunto de dados de entrada
2.3.2.2.4. A análise é feita através da construção de uma função que relaciona o uso de um determinado tipo de recurso(memória, tempo ou instruções) com os dados de entrada
2.3.2.2.5. Três situações básicas
2.3.2.2.6. Análise assintótica