
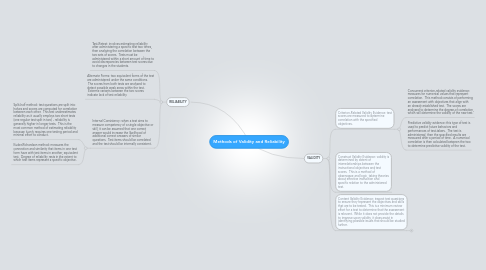
1. RELIABILITY
1.1. Test-Retest: involves estimating reliability after administering a specific test two times, then analyzing the correlation between the two sets of scores. Tests must be administered within a short amount of time to avoid discrepancies between test scores due to changes in the students.
1.2. Alternate Forms: two equivalent forms of the test are administered under the same conditions. The scores from both tests are analyzed to detect possible weak areas within the test. Extreme variants between the two scores indicate lack of test reliability.
1.3. Internal Consistency: when a test aims to measure competency of a single objective or skill, it can be assumed that one correct answer would increase the likelihood of additional correct answers of similar questions. Test items should be correlated and the test should be internally consistent.
1.3.1. Split-half method: test questions are split into halves and scores are computed for correlation between each other. This test underestimates reliability as it usually employs two short tests (one regular test split in two) - reliability is generally higher in longer tests. This is the most common method of estimating reliability because it only requires one testing period and minimal effort to conduct.
1.3.2. Kuder-Richardson method: measures the connection and similarity that items in one test form have with test items in another, equivalent test. Degree of reliability rests in the extent to which test items represent a specific objective.
2. VALIDITY
2.1. Criterion-Related Validity Evidence: test scores are measured to determine correlation with the specified objectives.
2.1.1. Concurrent criterion-related validity evidence: measures for numerical values that represent correlation. This method consists of performing an assessment with objectives that align with an already established test. The scores are analyzed to determine the degree of correlation, which will determine the validity of the new test.
2.1.2. Predictive validity evidence: this type of test is used to predict future behaviors and performances of test-takers. The test is administered, then the specified results are measured after a period of time. A numerical correlation is then calculated between the two to determine predictive validity of the test.
2.2. Construct Validity Evidence: validity is determined by extent of interrelationships between the instructional objectives and test scores. This is a method of observance and logic, taking theories about effective instruction and specific relation to the administered test.
2.3. Content Validity Evidence: inspect test questions to ensure they represent the objectives and skills that are to be tested. This is a minimum review effort for a test to determine that the assessment is relevant. While it does not provide the details to improve upon validity, it does assist in identifying possible issues that should be studied further.
2.3.1. New node