Unlock the full potential of your projects.
Try MeisterTask for free.
Don't have an account?
Sign Up for Free
Browse
Featured Maps
Categories
Project Management
Business & Goals
Human Resources
Brainstorming & Analysis
Marketing & Content
Education & Notes
Entertainment
Life
Technology
Design
Summaries
Other
Languages
English
Deutsch
Français
Español
Português
Nederlands
Dansk
Русский
日本語
Italiano
简体中文
한국어
Other
Show full map
Copy and edit map
Copy
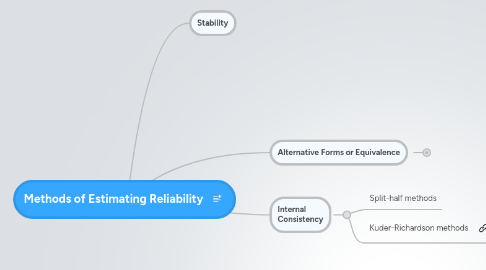
Methods of Estimating Reliability
Education & Notes
BM
Byron Murdaugh
Follow
Get Started.
It's Free
Sign up with Google
or
sign up
with your email address
Similar Mind Maps
Mind Map Outline
Methods of Estimating Reliability
by
Byron Murdaugh
1. Stability
2. Alternative Forms or Equivalence
2.1. New node
3. Internal Consistency
3.1. Split-half methods
3.2. Kuder-Richardson methods
Get Started. It's free!
Connect with Google
or
Sign Up