
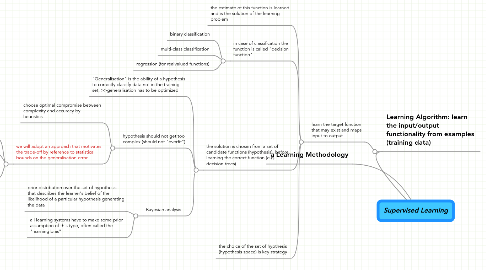
1. a Learning Methodology
2. Learning Algorithm: learn the input/output functionality from examples (training data)
2.1. learn the target function that may exist and maps input to output
2.1.1. the estimate of this function is learned and is the solution of the learning problem
2.1.2. in case of classification the function is called "decision function"
2.1.2.1. binary classification
2.1.2.2. multi-class classification
2.1.2.3. regression (for realvalued functions)
2.1.3. the solution is chosen from a set of candidate functions (hypothesis), before learning the correct function (e.g. decision trees)
2.1.3.1. "Generalisation" is the ability of a hypothesis to correctly classify data not in the training set; >>generalisation has to be optimized
2.1.3.2. hypothesis should not get too complex (should not "overfit")
2.1.3.2.1. choose optimal compromise between complexity and accuracy by heuristics
2.1.3.2.2. we will adopt an approach that motivates the trade-off by reference to statistical bounds on the generalisation error
2.1.3.3. Bayesian analysis
2.1.3.3.1. prior distribution over the set of hypothesis that describes the learner's belief of the likelihood of a particular hypothesis generating the data
2.1.3.3.2. all learning systems have to make some prior assumption of this type, often called the "learning bias"
2.1.4. the choice of the set of hypthesis (hypothesis space) is key strategy