
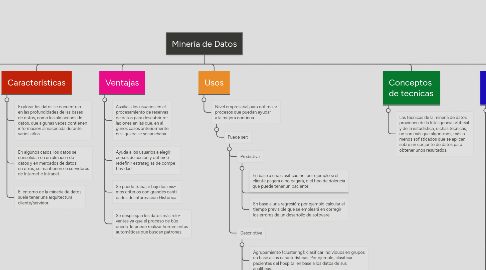
1. Características
1.1. Explorar los datos se encuentran en las profundidades de las bases de datos, como los almacenes de datos, que algunas veces contienen información almacenada durante varios años
1.2. En algunos casos, los datos se consolidan en un almacén de datos y en mercados de datos; en otros, se mantienen en servidores de Internet e Intranet.
1.3. El entorno de la minería de datos suele tener una arquitectura cliente/servidor.
2. Conceptos
2.1. La minería de datos es el proceso de detectar la información de grandes conjuntos de datos. Se vale para ello de el análisis matemático para deducir los patrones y tendencias que existen en los datos. Por lo general, estos patrones no se detectan mediante la exploración tradicional de los datos porque las relaciones son demasiado complejas o porque hay demasiado datos
2.2. El proceso de la minería de de datos consta de:
2.2.1. Definir el problema
2.2.2. Preparar los datos
2.2.3. Explorar los datos
2.2.4. Generar Modelos
2.2.5. Explorar y Validar modelos
2.2.6. Implementar y actualizar los modelos
3. Ventajas
3.1. Auxilia a los usuarios en el procesamiento de reservas de datos para descubrir re- laciones en las que, en al- gunos casos anteriormente ni si quiera se sospechaba
3.2. Ayuda a los usuarios a elegir cursos de acción y definir o redefinir estrategias de compe- titividad
3.3. Se puede trabajar bajo los mis- mos criterios con grandes canti- dades de información Histórica
3.4. Se despliegan los datos más rele- vantes ya que el proceso de bús- queda lo puede realizar herramientas automáticas que buscan patrones.
4. Conceptos de tecnicas
4.1. Las técnicas de la minería de datos provienen de la Inteligencia artificial y de la estadística, dichas técnicas, no son más que algoritmos, más o menos sofisticados que se aplican sobre un conjunto de datos para obtener unos resultados.
5. Usos
5.1. Nivel empresarial para optimizar procesos que puedan ayudar a la mejora continua
5.1.1. Puede ser:
5.1.1.1. Predictiva
5.1.1.1.1. En base a una clasificación: por ejemplo si el cliente pagará o no pagará, o el tipo de dolencia que puede tener un paciente.
5.1.1.1.2. En base a una regresión: por ejemplo calcular el tiempo previsible que se empleará en corregir los errores de un desarrollo de software.
5.1.1.2. Descriptiva
5.1.1.2.1. Agrupamiento (clustering): clasificar individuos en grupos en base a sus características. Por ejemplo, clasificar pacientes del hospital en base a los datos de sus analíticas.
5.1.1.2.2. Reglas de asociación: conocer cómo se relacionan los datos o campos. Por ejemplo conocer en el hipermercado que un cliente que compra leche muy probablemente comprará también pan.
5.1.1.2.3. Secuenciación: intentar predecir el valor de una variable en función del tiempo. Por ejemplo la demanda de energía eléctrica.
6. Tipos de Técnicas
6.1. Redes neuronales.- Son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales. Se trata de un sistema de interconexión de neuronas en una red que colabora para producir un estímulo de salida. Algunos ejemplos de red neuronal son:
6.1.1. -El Perceptrón. -El Perceptrón multicapa. -Los Mapas Autoorganizados, también conocidos como redes de Kohonen.